Predicting Insurance Fraud using SMOTE and MindsDB

Few interesting things about me:
- Software Engineer @ JP Morgan Chase & Co.
- AWS Community Builder 2023
- I love working with technology
- I enjoy playing video games 😄
Insurance fraud is a significant problem for the insurance industry, leading to serious financial losses and reputation damage. Big data has created more opportunities than ever before for the insurance business to engage in fraudulent operations.
To find patterns and anomalies that can point to fraud, we can make use of machine learning and its capabilities to provide conclusive evidence of fraudulent activities.
Observing the data
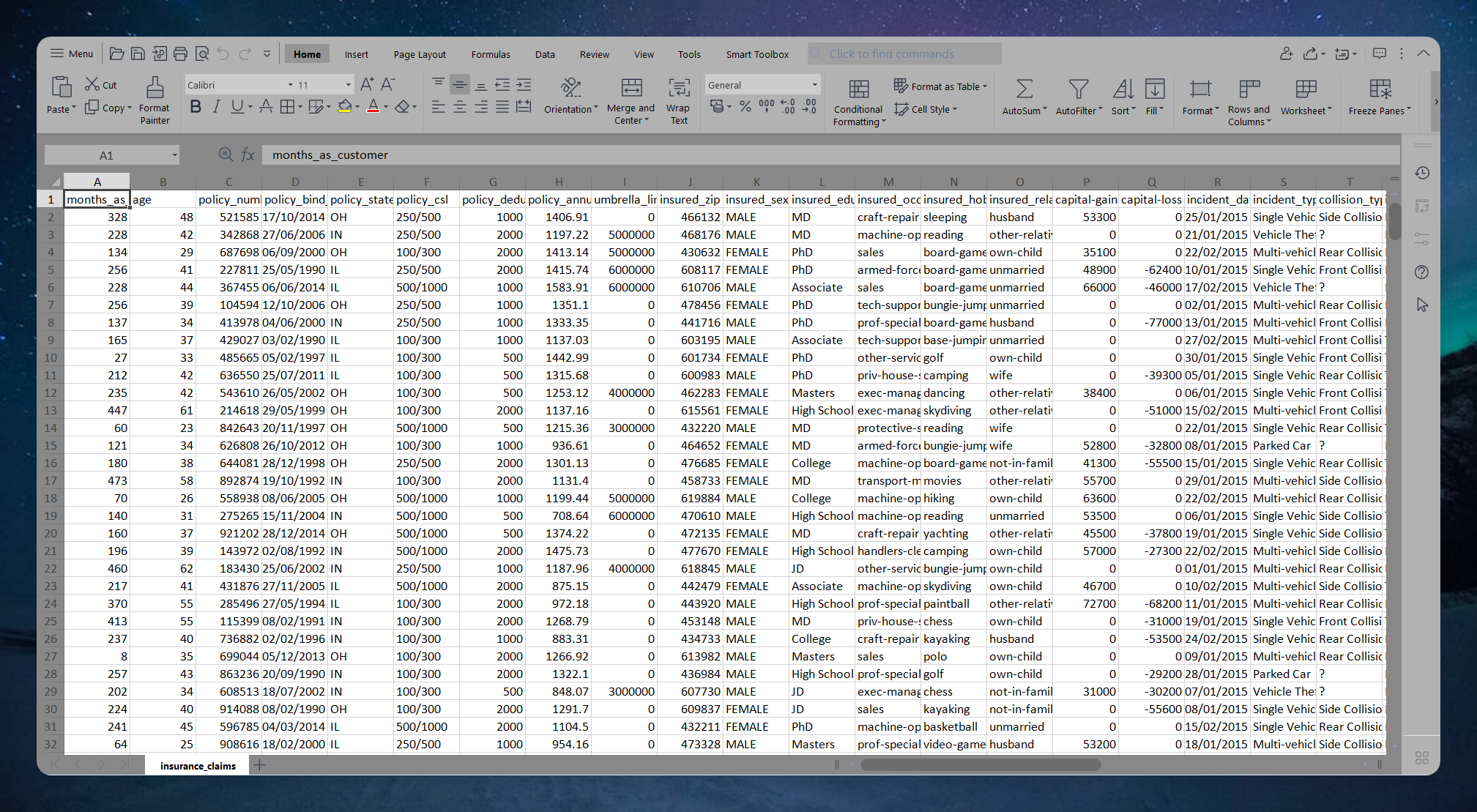
Our dataset contains insurance claim logs from an automobile insurance company in the United States. We have customer information, policy identifiers, premium payment information, and other payment-related data. But most importantly, we have information about the incident, including the date, type of collision (not applicable if the car was stolen), time of day, witnesses, injuries, and other details across seven states. There are initially 1000 rows and 41 columns in our dataset.
Our target column is: fraud_reported
We can sense that it's a classification problem.
Now ideally, one could just dump this dataset into MindsDB, train a model and get done with the job. But it probably isn't the best approach.

Okay, I tried it 😂 and was able to get 88.5% accuracy, which isn't half bad for a classification model given the number of features we were dealing with, but we can certainly get more.
Let's take a step back and open this up on a Jupyter Notebook!
Data Preprocessing
I didn't do too much work here, just the usual stuff, removing irrelevant rows, data transformation, etc.
df = pd.read_csv(path)
df.shape
#! (1000,40)
df.policy_number.nunique()
#! 1000
## Removing a useless column (never knew why it was there in the first place)
df = df.drop(['_c39'],axis=1)
## Convert the policy_bind_date column to a datetime format
df['policy_bind_date'] = pd.to_datetime(df['policy_bind_date'])
## Extract the year, month, and day from the policy_bind_date column
df['policy_bind_year'] = df['policy_bind_date'].dt.year
df['policy_bind_month'] = df['policy_bind_date'].dt.month
df['policy_bind_day'] = df['policy_bind_date'].dt.day
## Drop the original policy_bind_date column
df = df.drop('policy_bind_date', axis=1)
## Replace question marks with more sensible information
df['collision_type']=df['collision_type'].replace("?","Not Applicable")
df['police_report_available']=df['police_report_available'].replace("?","Unknown")
# Remove irrelevant columns
df=df.drop(['incident_date'],axis=1)
After this, I did a little bit of feature engineering to transform categorical data into numerical.
# A simple form of OneHot Encoding to get numerical data out of categorical
df=pd.get_dummies(df,columns=['policy_csl', 'insured_education_level','insured_occupation', 'insured_hobbies', 'insured_relationship', 'incident_type', 'collision_type', 'incident_severity', 'incident_state', 'insured_zip', 'authorities_contacted', 'auto_make', 'auto_model', 'policy_state', 'insured_sex','capital-loss', 'capital-gains', 'incident_city', 'incident_location', 'property_damage', 'police_report_available'], drop_first=True)
After this, we come across an interesting metric:
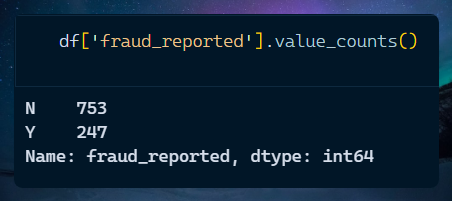
As you'd expect, the number of fraud cases is way lesser than the non-fraud ones.
This begs the question, is it safe to drop them as-is to a machine learning model?
Applying SMOTE
Most machine learning (prediction) models work ideally when the number of samples in each class is almost equal. These algorithms are made to minimize errors and maximize accuracy.
When there is a significant imbalance of class, it would give significantly less priority to the minority class while making the prediction.
Even in our dataset, if you'd predict every row as non-fraud, you'd still be 75.3% accurate, which is still a good score, but it ain't a machine learning model.
While there are different resampling techniques to fix this issue, I decided to go with SMOTE, which stands for "Synthetic Minority Oversampling Technique".
What is SMOTE?
This technique is used to generate synthetic data for minority classes, in our case, the fraud class.
It randomly picks a point from the minority class and calculates the k-nearest neighbours to that point. These points are added between the chosen point and the neighbours.
Before applying SMOTE, I'm going to use a RandomForestClassifier to generate the best features from our dataset. These are features that contribute the most to the "fraud_reported" result.
### Generating best features
# Load data and split into features (X) and target (y)
X = df.drop('fraud_reported', axis=1)
# Create random forest classifier object
rfc = RandomForestClassifier(n_estimators=300)
# Train model
rfc.fit(x, y)
# Get feature importances
importances = rfc.feature_importances_
# Sort feature importances in descending order
indices = np.argsort(importances)[::-1]
top_500_indices = indices[:500]
top_500_features = X.columns[top_500_indices]
# Update X to include only top 500 features
X = X[top_500_features]
Finally, I'll apply fit this in a SMOTE class instance.
%pip install imblearn
from imblearn.over_sampling import SMOTE
x_upsample, y_upsample = SMOTE(random_state=42).fit_resample(x, y)
Now that we're done with the preprocessing and feature engineering, I'm going to dump this dataset into a CSV file.
new_df = pd.concat([x_upsample, y_upsample], axis=1)
# Save the merged dataframe to a CSV file
new_df.to_csv('updated_fraud_insurance_claims_dataset.csv', index=False)
Setting up MindsDB
Instead of using MindsDB on the free provided cloud instance, I took the fancy route to self-host it on an AWS EC2 instance. I liked it so much that I made a video about it.
Creating a Model on MindsDB
I simply used their UI to upload the dataset I just generated.
CREATE MODEL mindsdb.insurance_claims_fraud_predictor
FROM files
(SELECT * from fraud_dataset)
PREDICT fraud_reported;
I then ran this simple SQL query to create a model on MindsDB.
Making Predictions on MindsDB

As you can see, we have a much better accuracy than before. Our accuracy is now 94%.
SELECT t.policy_number,t.fraud_reported AS EXPECTED_TARGET, m.fraud_reported AS PREDICTED_FRAUD_REPORTED, m.fraud_reported_explain
FROM files.fraud_dataset AS t
JOIN mindsdb.insurance_fraudulent_claims_predictor AS m
LIMIT 10;
After this, I just ran some batch predictions on the same data using this query.
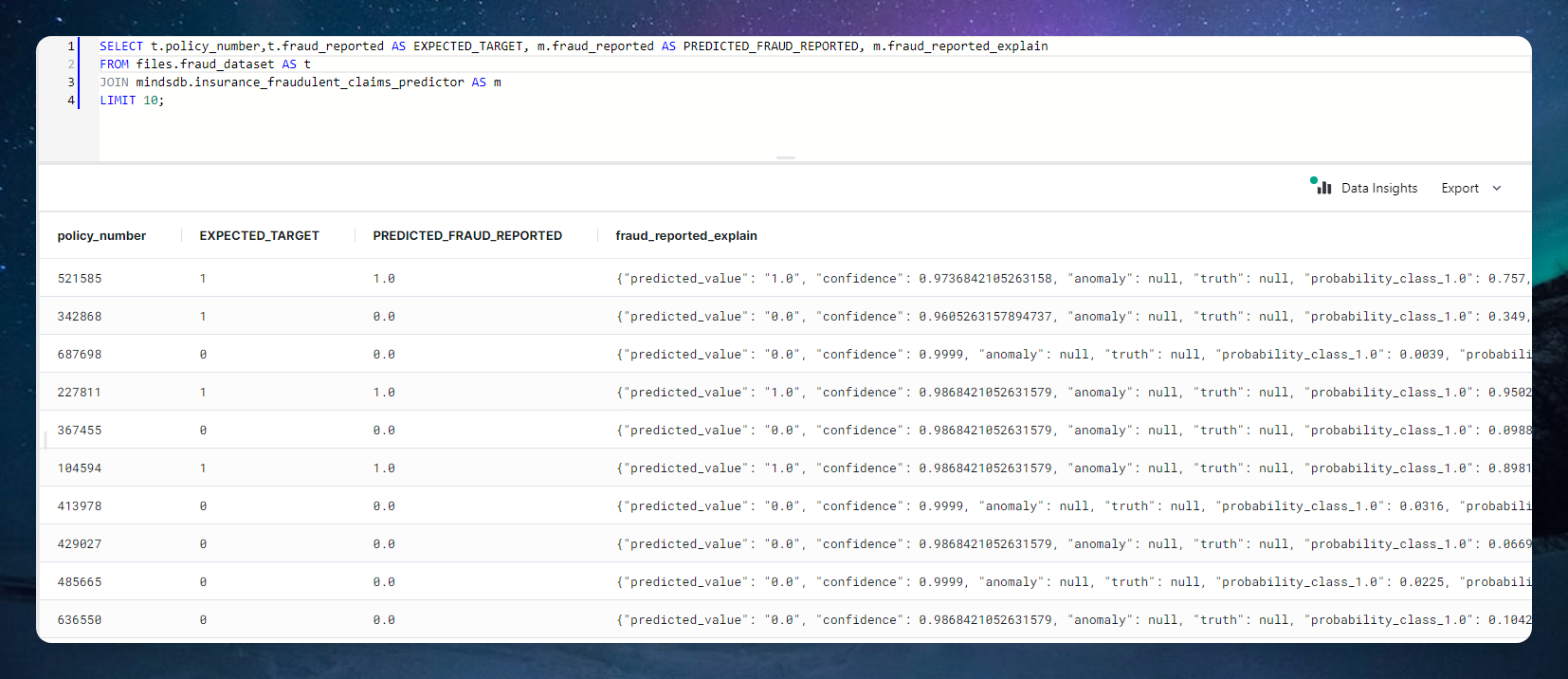
As you'd expect, we get the right result 9 out of 10 times.
It was fun working on Machine Learning after a long time, thanks to this hackathon from MindsDB and Hashnode. It was fun working with it, I even tried to make a tiny contribution to their documentation.
Looking forward to more of these competitions. Until next time, cheers!